在当今信息爆炸的时代,高效地获取和处理网络数据已成为企业和机构的重要需求。网络爬虫(Web Crawler)作为一项核心技术,在北京计算机系统服务领域扮演着越来越关键的角色。本文将从网络爬虫的基本原理入手,探讨其在计算机系统服务中的应用与挑战。
一、网络爬虫的定义与工作原理
网络爬虫,又称网络蜘蛛或网络机器人,是一种按照预设规则自动抓取互联网信息的程序或脚本。其核心工作原理可概括为以下几步:
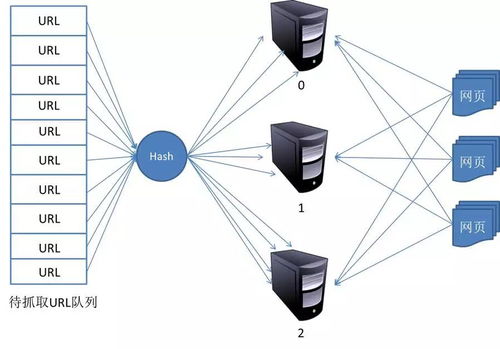
- 种子URL设定:爬虫从初始的URL列表(种子URL)开始工作,这些URL通常由用户指定。
- 页面抓取:爬虫通过HTTP/HTTPS协议访问目标网页,下载页面内容(通常是HTML代码)。
- 数据解析:解析下载的页面,提取有用信息(如文本、图片链接等),并识别页面中的其他链接。
- 链接追踪:将新发现的链接加入待抓取队列,循环执行抓取和解析过程,直到满足停止条件(如达到深度限制或抓取数量)。
- 数据存储:将提取的结构化数据保存到数据库或文件中,供后续分析使用。
二、网络爬虫的关键技术要点
- 请求与响应处理:爬虫需要模拟浏览器行为发送请求,并处理服务器的响应(包括状态码、重定向等)。
- 解析技术:常用HTML解析库(如BeautifulSoup、lxml)或正则表达式来提取数据,现代爬虫也常结合JavaScript渲染工具(如Selenium)处理动态页面。
- 去重策略:通过哈希算法或布隆过滤器避免重复抓取相同URL,提高效率。
- 遵守robots协议:尊重网站的robots.txt文件,避免抓取被禁止的页面,体现合法合规性。
- 反爬虫应对:针对IP封锁、验证码等反爬机制,需采用代理IP池、请求头伪装或延迟请求等技术。
三、网络爬虫在北京计算机系统服务中的应用
北京作为科技创新中心,其计算机系统服务行业广泛利用网络爬虫技术支撑业务发展:
- 市场调研与竞争分析:企业通过爬虫收集行业数据、产品价格和用户评论,辅助决策制定。
- 舆情监控:政府或机构实时抓取新闻、社交媒体信息,及时感知公众意见和突发事件。
- 垂直信息聚合:在招聘、房产、电商等领域,服务商整合多平台数据提供一站式查询服务。
- 学术与科研:高校及研究机构抓取公开论文、专利数据,支持学术分析与技术创新。
- 安全监测:网络安全公司利用爬虫扫描漏洞、追踪威胁情报,增强系统防护能力。
四、挑战与合规性考量
在北京开展计算机系统服务时,网络爬虫的应用需注意以下问题:
- 法律与伦理边界:严格遵守《网络安全法》等法规,避免侵犯隐私、知识产权或构成不正当竞争。
- 数据安全:确保抓取的数据存储与传输安全,防止泄露敏感信息。
- 资源消耗控制:合理设置抓取频率,避免对目标网站服务器造成过大压力。
- 技术更新适应:随着网站反爬技术升级,爬虫系统需持续优化以保持有效性。
五、未来发展趋势
在北京计算机系统服务的推动下,网络爬虫技术正朝着智能化、分布式和合规化方向发展:
- AI融合:结合自然语言处理和机器学习,提升数据提取的准确性和语义理解能力。
- 云化与分布式架构:利用云计算资源实现大规模并发抓取,提高效率和可扩展性。
- API优先策略:越来越多网站提供开放API,鼓励合法数据交换,减少对爬虫的依赖。
- 合规自动化工具:开发集成法律规则检测的爬虫系统,自动规避合规风险。
网络爬虫作为连接海量网络数据与计算机系统服务的桥梁,其基本原理的深入理解和正确应用,对于北京乃至全国的数字化转型具有重要意义。服务提供商应在技术创新与合规经营之间找到平衡,以促进健康、可持续的数据生态发展。